멀티 스레드는 왜 필요할까?
멀티 스레드(multi thread)란 하나의 프로세스 내에 둘 이상의 스레드가 동시에 작업을 수행하는 것을 말한다. 멀티 프로세스(multi process)란 여러 프로세스를 동시에 수행하는 것을 의미한다.
멀티 스레드가 단일스레드와 멀티 프로세스에 비해 가지는 이점은 무엇일까?
1. 성능 개선 : 병렬 처리를 통한 응답속도와 처리량 향상

멀티 코어 프로세서를 이용할 수 있게 되면서 병렬 처리가 가능해졌다. 병렬 처리로 여러 개의 작업을 물리적으로 동시에 실행시켜서 응답속도와 처리량을 향상시킬 수 있게 되었다.
2. 자원 절약 : 프로세스보다 적은 메모리 및 시스템 자원 소비
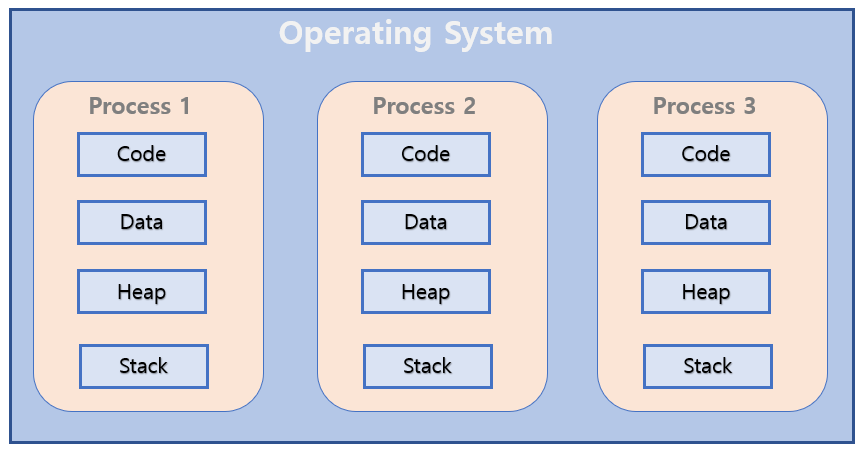

프로세스는 1개 생성 시, 스태틱 영역(메소드 영역), 힙 영역, 스택 영역에 관해 모두 메모리를 할당해야 하는 반면, 스레드는 스택 영역만 할당하면 된다.
3. 빠른 전환, 높을 활용도 : 멀티 스레드의 컨텍스트 스위치 비용 감소로 CPU 이용률 상승
스레드는 프로세스에 비해 컨텍스트 스위칭(Context Switching) 으로 인한 오버헤드가 작다. 그 이유는 스레드 컨텍스트 스위칭이 발생했을 때, CPU는 스택 영역의 메모리와 레지스터 주소를 포함한 스레드 컨텍스트(context) 정보만을 변경하면 된다. 그러나, 프로세스 컨텍스트 스위칭이 발생했을 때는 CPU는 프로세스가 사용하던 캐시 매모리 내역도 지워줘야 하고, 프로세스 전체 컨텍스트 정보를 변경해야 된다. 멀티 스레드 환경에서 컨텍스트 스위칭 오버헤드가 감소하여 프로그램 실행에 CPU를 더 많이 이용할 수 있다. 즉, CPU 이용률이 상승하게 된다.
멀티 스레드 프로그래밍 시 발생할 수 있는 문제점
race condition : 공유 데이터 동시 접근으로 인한 데이터 불일치 문제 발생
자바에서 스레드들은 스태틱 영역과 힙 영역을 공유하고 있다. 이러한 공유 데이터에 여러 스레드들이 동시에 접근할 때 데이터 불일치 문제가 발생할 수 있다. 이러한 상황을 race condition이라고 한다.
race condition(경쟁 상태)
- 여러 스레드들이 동시에 공유 데이터에 접근하는 상황
- 데이터의 최종 연산 결과는 마지막에 그 데이터를 다룬 스레드에 따라 달라진다.
일관성 유지를 위해서는 스레드 간의 실행 순서를 정해주는 매커니즘이 필요하다. 즉, race condition을 막기 위해서는 스레드 동기화가 이루어져야 한다.
이제 자바에서 스레드 동기화를 하는 방법 세가지에 대해서 알아보도록 하겠다.
race condition에 대한 해결책 : 스레드 동기화
스레드 동기화를 위해선 두가지 조건을 만족시켜야 한다.
- 배타적 실행 : 한 스레드가 변경 중이라서 상태가 일관되지 않을 때, 다른 스레드가 접근하지 못하게 막는다.
- 가시성 : 한 스레드에서 이루어진 변화를 다른 스레드에서 확인할 수 있어야 한다.
각각의 방법에 대해서 1번과 2번 조건을 어떻게 만족시키는지 살펴보도록 하겠다.
synchronized 키워드: 공유 데이터 접근 제어를 위한 기본 동기화 메커니즘
자바는 멀티스레드 환경에서 스레드 동기화를 지원하기 위해 기본적으로 고유락(Intrinsic Lock, 모니터락(Monitor Lock))을 지원한다. synchronized 키워드를 이용해서 특정 객체의 고유락을 사용해 스레드를 동기화시킬 수 있다.
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
}이런식으로 메소드 또는 특정 블록을 synchronized로 묶을 수 있다. 이 코드는 아래의 코드와 동일하다.
public class Counter {
private int count = 0;
public void increment() {
synchronized (this) {
count++;
}
}
}이 코드에서 Counter의 인스턴스를 고유락으로 사용하였다. Counter의 인스턴스를 이용하여 여러 스레드가 동시에 count 변수에 접근하지 못하도록 했다. 한 스레드가 Counter 인스턴스의 고유락을 획득한 경우, 다른 스레드는 blocked 상태가 되어, 락을 획득한 스레드의 실행이 끝나고 반환할 때까지 기다려야 한다. 이를 통해 스레드 동기화의 첫번째 조건인 배타적 실행을 만족시킴을 알 수 있다. 또한 자바는 synchronized 블록에 진입하기 직전에 CPU 캐시 메모리와 메인 메모리 값을 동기화하여 가시성을 해결한다.
하지만 synchronized를 이용한 스레드 동기화 방법은 성능 저하가 발생한다. 그 이유는 첫번째로, 해당 객체의 고유 락에 접근하는 스레드들은 blocked 상태가 되어 다른 작업을 하지 못하기에 CPU 이용률이 떨어지게 되기 때문이다. 두번째로 blocked 상태의 스레드들이 고유 락을 얻게 되면, ready 혹은 running 상태로 변경하기 위해 시스템 자원을 사용해야 하기 때문이다. 따라서 synchronized를 이용한 방법보다는 다른 방법을 이용하는 것이 좋다.
volatile 변수 : race condition은 해결할 수 없다!
또 다른 스레드 동기화 방법인 Atomic 클래스를 알아보기 전에, 스레드의 동기화 조건 중 가시성만 만족시키는 volatile 변수에 대해서 알아보도록 하자.
volatile 키워드는 항상 가장 최근에 기록된 값을 읽는 것을 보장한다. volatile 변수에 대한 읽기 및 쓰기 작업은 즉시 메인 메모리에서 읽어오고 저장하는 방식으로 동작하여 한 스레드가 값을 변경하면 다른 스레드가 확인할 수 있기 때문이다. 즉 가시성을 만족시킨다.
하지만 volatile 키워드는 메인 메모리에서 값을 읽거나, 특정한 값으로 수정하는 원자적 연산이 아닌 경우, 배타적 실행은 만족시킬 수 없다.
아래의 코드를 통해 살펴보도록 하자.
public class Counter {
private volatile int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}위의 코드는 배타적 실행을 지원하지 않는다. 그 이유는 count++ 이라는 증가 연산자에서 발생한다. 코드 상으로는 하나의 연산이지만, 실제로는 count 라는 공유 변수에 두번 접근한다. 먼저 count 값을 읽고, 다음에 1 증가한 새로운 값을 count 변수에 저장한다. 만약 두번째 스레드가 이 두 접근 사이에 값을 읽어가면 첫번째 스레드와 동일한 값을 돌려 받게 되고, 배타적 실행이 이루어지지 않아 데이터 불일치 문제가 발생한다.
Atomic 클래스 : CAS 알고리즘으로 데이터 불일치 문제 해결
java.util.concurrent.atomic 패키지의 Atomic 클래스를 이용하면 락 없이도 스레드 동기화를 할 수 있다. Atomic 클래스는 volatile 변수를 이용하여 가시성을 만족시키고, 추가로 CAS(Compare And Swap) 알고리즘을 이용해서 배타적 실행을 보장한다.
CAS 알고리즘은 다음과 같은 과정으로 진행된다.

- 인자로 스레드가 읽은 기존 값(Compared Value)과 변경할 값(New Value)를 전달한다.
- CPU 캐시 메모리에 있는 기존 값이 현재 메인 메모리가 가지고 있는 값(Destination)과 동일하면 변경할 값을 메인 메모리에 반영하고 true를 반환한다.
- 반대로 기존 값이 현재 메인 메모리가 가지고 있는 값(Destination)과 다르다면 변경할 값을 메인 메모리에 반영하지 않고 false를 반환한다.
- false를 반환하는 경우 무한 루프를 돌면서 같은 시도를 반복하거나 다른 작업을 하게 된다.
CAS 알고리즘은 스레드가 동시에 접근하여, 스레드가 처음 메인 메모리에서 읽어들인 값과 변경한 값을 저장할 때의 메인메모리에서 읽어들인 값이 다르면, 변경사항이 반영되지 않도록 해준다. 따라서 CAS 알고리즘을 통해 배타적 실행을 보장된다.
이러한 CAS 알고리즘을 활용하면 스레드가 blocked 상태가 되지 않아서 무한루프를 돌다가 메인 메모리 값과 스레드가 읽은 값이 같으면 true를 반환 받고 스레드 상태 변경 없이 바로 이후 작업을 이어서 할 수 있다.
AtomicLong 클래스를 통해, 더 자세히 살펴 보자. volatile 변수에서 발생했던 데이터 불일치 문제를 java.util.concurrent.atomic 패키지의 AtomicLong 클래스를 이용해서 해결했다.
public class Counter {
private AtomicLong count = new AtomicLong();
public void increment() {
count.getAndIncrement();
}
public long getCount() {
return count.get();
}
}
아래의 코드는 AtomicLong 클래스의 구현부 중 이 글에서 주목하는 부분만 가져온 것이다. 우선 value 변수를 volatile 변수로 지정하여 가시성을 만족시킴을 알 수 있다.
AtomicLong 클래스의 get()과 set() 메소드는 값을 읽고, 저장하는 메소드로, 그 자체로 하나의 연산, 즉 원자성이 보장되기 때문에, CAS 알고리즘을 사용하지 않고, 메인 메모리에서 값을 읽고 저장한다.
연산의 원자성이 보장되지 않아 데이터 불일치의 문제가 발생했던 증가 연산자를 AtomicLong 클래스의 getAndIncrement() 메소드로 바꿔 배타적 실행이 가능해졌다.
public class AtomicLong extends Number implements java.io.Serializable {
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicLong.class, "value");
private volatile long value;
public final long getAndIncrement() {
return U.getAndAddLong(this, VALUE, 1L);
}
public final long get() {
return value;
}
public final void set(long newValue) {
// See JDK-8180620: Clarify VarHandle mixed-access subtleties
U.putLongVolatile(this, VALUE, newValue);
}
}getAndIncrement() 메소드 내부에서 CAS 알고리즘 로직을 활용한 것을 볼 수 있다. weakCompareAndSetLong() 메소드에서 메인 메모리에 저장된 값과 현재 스레드가 읽어들인 값이 동일하면, 메인 메모리에 변경한 값을 저장하고 true를 반환하여 while 문을 빠져 나온다.
public final class Unsafe {
@HotSpotIntrinsicCandidate
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v = getLongVolatile(o, offset);
} while (!weakCompareAndSetLong(o, offset, v, v + delta));
return v;
}
}Concurrent Collection : 동기화 블록 범위 최소화로 성능 향상
Concurrent Collection(동시성 컬렉션)은 Synchronized Collection(동기화된 컬렉션) 보다 성능이 좋다.
Java 8 API에 의하면, ConcurrentHashMap은 동기화된 HashMap보다 선호되고, ConcurrentSkipListMap은 동기화된 TreeMap에 비해 선호된다. 또한 CopyOnWriteArrayList는 동기화된 ArrayList보다 선호된다.
Synchronized Collection은 메소드에 synchronized 키워드를 적용하여 메소드 전체 블록을 락을 통해 동기화하여 성능이 떨어진다. 또한 여러 연산을 하나의 단일 연산처럼 활용해야 하는 경우, 여러 연산을 묶어 synchronized 블록으로 지정해야 한다. 불필요하게 락을 얻고 해제하는 과정이 많아지므로 이 또한 성능 저하로 이어질 수 있다.
반면에 Concurrent Collection은 synchronized 블록이 필요한 부분만 synchronized 블록으로 지정한다. 또한 Concurrent Collection은 다수의 동시적으로 일어나는 읽기와 쓰기를 스레드 안전하게 보장한다. 다수의 스레드가 컬렉션에 스레드 안전하게 동시에 접근하는 것이 가능하다.
Concurrent Collection 중 하나인 ConcurrentHashMap과 Sycnhronized Collection인 HashTable, 스레드 안전하지 않은 HashMap을 비교하면서, Concurrent Collection의 이점을 살펴보겠다.
ConcurrentHashMap은 HashTable, HashMap과 동일하게 해시를 기반으로 하는 Map이다. 스레드 안전하지 않은 HashMap과는 달리 모든 동작이 스레드 안전하지만, 검색 작업은 락을 수반하지 않고, 전체테이블에 대한 접근을 막는 락도 지원하지 않는다. HashTable과 동일하게 스레드 안전하지만, synchronized 블록 범위가 좁다.

위의 그림에서 볼 수 있듯이 ConcurrentHashMap은 각 테이블 버킷을 독립적으로 스레드 동기화한다.


이로 인해 각 요소를 병렬적으로 처리할 수 있게 되었다. 빈 버킷에 노드를 넣을 경우, CAS 알고리즘을 활용하여, 스레드가 blocked 되지 않은 상태에서도 스레드 동기화를 처리했다. 버킷에 노드가 있을 경우 첫번째 노드 객체의 고유 락을 사용하여 부분적으로 synchronized 블록을 지정하였다. HashTable, HashMap, ConcurrentHashMap을 정리하면 다음과 같다.
| HashTable | HashMap | ConcurrentHashMap | |
|---|---|---|---|
| 스레드 안전 | O | X | O |
| 성능 (싱글 스레드 기준) | 가장 나쁘다 | 가장 좋다 | 중간 |
| 병렬처리 | 과도한 동기화로 인한 성능 저하 | race condition 발생할 수 있음 | 성능 좋음 |
정리
- 멀티 스레드 환경에서 발생할 수 있는 문제 : race condition
- 스레드 동기화를 할 수 있는 방법 :
- synchronized 블록 사용 : 락을 얻고 해제하는데 오버헤드가 커서 잘 사용하지는 않음
- java.util.concurrent 패키지의 클래스 사용 : Atomic 클래스, Concurrent Collection 이용
참고자료
- KOCW 운영체제 강의 - 반효경
- 이펙티브 자바 - item78, 81
- java.util.concurrent 패키지
- CAS(compare and swap)
- ConcurrentHashMap : https://highright96.tistory.com/113
- 그림 출처 :
- ConcurrentHashMap : https://javatrainingschool.com/concurrenthashmap-in-java/
- ConcurrentHashMap2 : https://www.javamadesoeasy.com/2015/04/concurrenthashmap-in-java.html
- ConcurrentHashMap3 : https://javaconceptoftheday.com/synchronized-hashmap-vs-hashtable-vs-concurrenthashmap-in-java/
'(컴퓨터 언어)Java' 카테고리의 다른 글
| JVM이란?. (3) | 2024.09.15 |
|---|---|
| java.util.Stack, 실제로는 잘 사용하지 않는 이유는? (0) | 2023.07.31 |

댓글